

Закон «імені себе» Джордж Зіф відкрив, удосконалюючи методику викладання іноземної мови. Процес вивчення чужої мови включає розширення словникового запасу. Щоб говорити мовою, треба вивчити слова цієї мови.
Очевидно, що взяти словник, прочитати його від кірки до кірки та вивчити багато тисяч слів — не найкращий спосіб. Адже одні слова зустрічаються у мові частіше, інші — рідше. Деякі — дуже рідко. Ви знаєте, що таке тантамареска? І чим вона відрізняється від Тінтамара?
Тому для впевненого володіння іноземною мовою слід насамперед вивчити найвживаніші слова, яких насправді не так вже й багато — близько 2000. Та й ці слова бажано вивчати не поспіль, не в алфавітному порядку.
Спочатку слід освоїти найчастіше вживані у мові слова, потім — слова, що використовуються рідше, і, нарешті, слова, що застосовуються дуже рідко, прикраси та індивідуалізації промови. Тому, якщо й вивчати іноземні слова за словником, то словник цей має бути не алфавітним, а частотним.
У частотному словнику слова розташовуються за алфавітом, а, по частоті встречаемости в текстах іноземною мовою. Наприклад, слово, яке в корпусі з мільйона слів зустрінеться 100 тисяч разів, у частотному словнику стоятиме раніше слова, частота народження якого 10 тисяч разів на мільйон. У свою чергу, це друге слово перебуватиме в частотному словнику ближче до початку, ніж слово, що зустрічається лише 1 тисячу разів на 1 мільйон слів.

Звичайно, першими словами в частотному словнику будуть службові слова: прийменники, артиклі та інші. Слова ці, як правило, короткі і велике смислове навантаження не несуть. Але вже в першому десятку слів з'являться і значущі слова. Саме ці слова слід давати студенту під час навчання насамперед. Саме в цей момент студенту, а ще викладачеві, потрібен частотний словник мови, що вивчається.
Справа за малим — порахувати частоту всіх слів певної мови і розташувати слова в міру спадання цього параметра. Тут бачаться принаймні дві проблеми.
По-перше , вибрати текст або групу текстів, які могли б представляти всю мову. Такий набір називають ще корпусом язика. Обсяг корпусу мови повинен бути не менше 1 мільйона слів, а складати його слід із різних джерел, від газетних статей до класичних текстів. Склад мовного корпусу визначає результати всієї роботи. Тому підбір текстів, що утворюють корпус мови, — справа відповідальна. Більше того, це справа, яка потребує справжнього філологічного чуття.
Друга проблема – це власне розрахунок частоти народження слів у певному корпусі мови. Раніше це була справа просто технічно складна. Зараз же просту програму для комп'ютера, що вважає частоту народження слів, може написати і кмітливий школяр. Але проблем від цього не поменшало, вони просто перейшли на інший рівень складності.
Можливо тому частотні словники з'явилися відносно недавно. Перший такий словник англійської мови, «Teacher's Word Book», побачив світ у 1921 році. Цей словник включав 10 тисяч найуживаніших англійських слів. 1944 року його було перевидано у збільшеному обсязі (30 тисяч слів).
Перший частотний словник російської теж був виданий США 1953 року. Цей словник містив близько 5 тисяч різних слів. Перший частотний словник сучасної російської з'явився 1963 року у Таллінні. У ньому було представлено 2.5 тисяч найуживаніших слів. У 1977 року було видано перший частотний словник російської, який створили з допомогою комп'ютера з урахуванням корпусу текстів 1 мільйон слів.
У будь-якому випадку зрозуміло, чому, будучи викладачем іноземної мови в Гарвардському університеті, Зіф зацікавився проблемою частоти слів у мові. Його перша робота у цій галузі вийшла у 1932 році.
Зіф та його студенти китайського походження досліджували частоту розподілу слів у таких далеких один від одного мовах, як латина та китайська. У цій роботі та в кількох наступних роботах з вивчення частоти народження слів у природних мовах була виявлена закономірність, яку пізніше назвали «законом Ципфа»:
Твір частоти слова і його позиції в частотному словнику — величина приблизно постійна .
Значення цієї постійної величини відрізняється різними мовами.
Закон Ципфа можна ще сформулювати і так:
Частота народження слова в тексті знаходиться приблизно у зворотному пропорційної залежності від його порядкового номера в списку частотності .
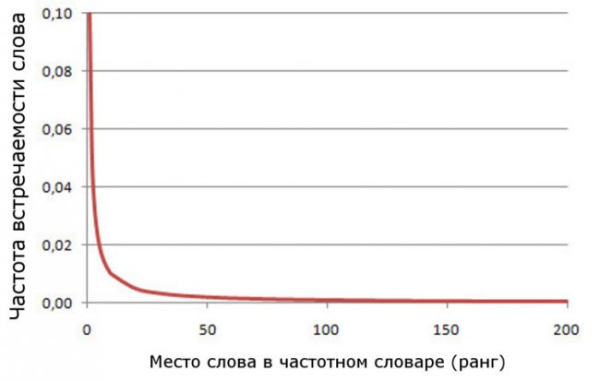
Це означає, що друге за частотою використання слово буде зустрічатися в корпусі слів приблизно вдвічі рідше, ніж перше. Так само третє слово буде зустрічатися втричі рідше, ніж перше, і таке інше. Крива, що описує закон Ципфа — гіпербола, що досить швидко спадає і з майже горизонтальним «хвістом», що тягнеться потім. У спадній частині цієї кривої знаходяться найуживаніші слова, а в хвості — слова, що вживаються рідко. Зате саме в цій частині відбувається багато чудес, про які буде сказано нижче.
У лінгвістиці закон Ципфа зіграв велику роль, оскільки він був першою математичною закономірністю, виявленої щодо мов. Важливою була навіть така конкретна форма залежності. Головне, було знайдено параметр, досліджуючи який, можна було отримувати інформацію про, так би мовити, внутрішній устрій мови. Таким параметром виявилася частота слів у тексті.
Для математиків та фахівців з математичної статистики закон, відкритий лінгвістом Зіфом, одкровенням не був. З погляду математичної статистики закон Ципфа є окремим випадком іншого статистичного розподілу, розподілу Парето. Марк Блау, особистий архів
Цей розподіл названо на ім'я відомого італійського інженера, економіста та соціолога Вільфредо Парето (1848 -1923) . Закон Парето стосується не якихось абстрактних предметів, а явищ, з якими ми зустрічаємось на кожному кроці.
Найбільш відоме формулювання цього закону зветься «20 до 80». Наприклад, 20% населення будь-якій країні володіють 80% національного багатства.
Інший прояв закону Парето — втіха для ледарів та втіха для перфекціоністів. Виконання 80% будь-якої роботи потребує 20% зусиль. А 80% зусиль витрачається на те, щоб завершити 20% роботи, що залишилися.
pinterest.com
Пояснення закону Ципфа з погляду теорії передачі дав геніальний математик Бенуа Мандельброт (1924 — 2010) . Коротко пояснення Мандельброта виглядає так.
Мова — це засіб комунікації, й у його функціонування діють закономірності, справедливі будь-якого каналу связи. З одного боку, збільшення кількості слів під час передачі інформації подовжує час комунікації. З іншого боку, воно зменшує ймовірність помилки під час передачі повідомлення, отже, скорочує час комунікації з допомогою те, що немає потреби у повторної передачі.
Компроміс між цими двома взаємно суперечать вимогами призводить до того, що найчастіше вживаються коротші слова. Математична модель процесу комунікації, яку запропонував Мандельброт, призводила до дещо модифікованого рівняння закону Ципфа.
При цьому ставав зрозумілим фізичний зміст параметрів, що входять до цього рівняння. З'являлася навіть можливість оцінити, наскільки великий словниковий запас того, хто говорить, тобто наскільки він інтелігентний.
Далі буде …